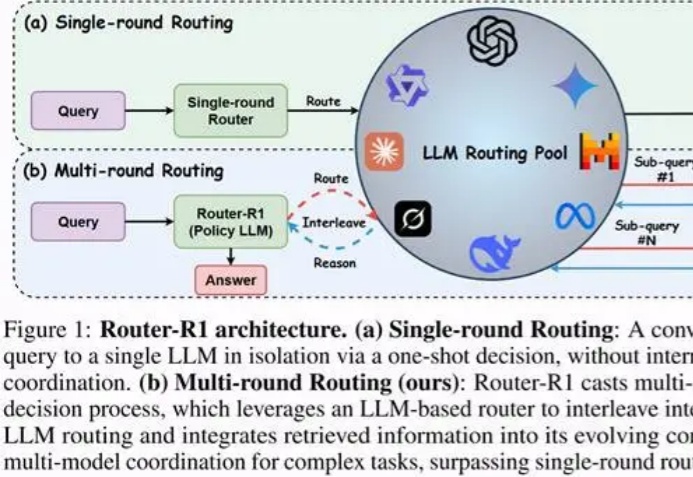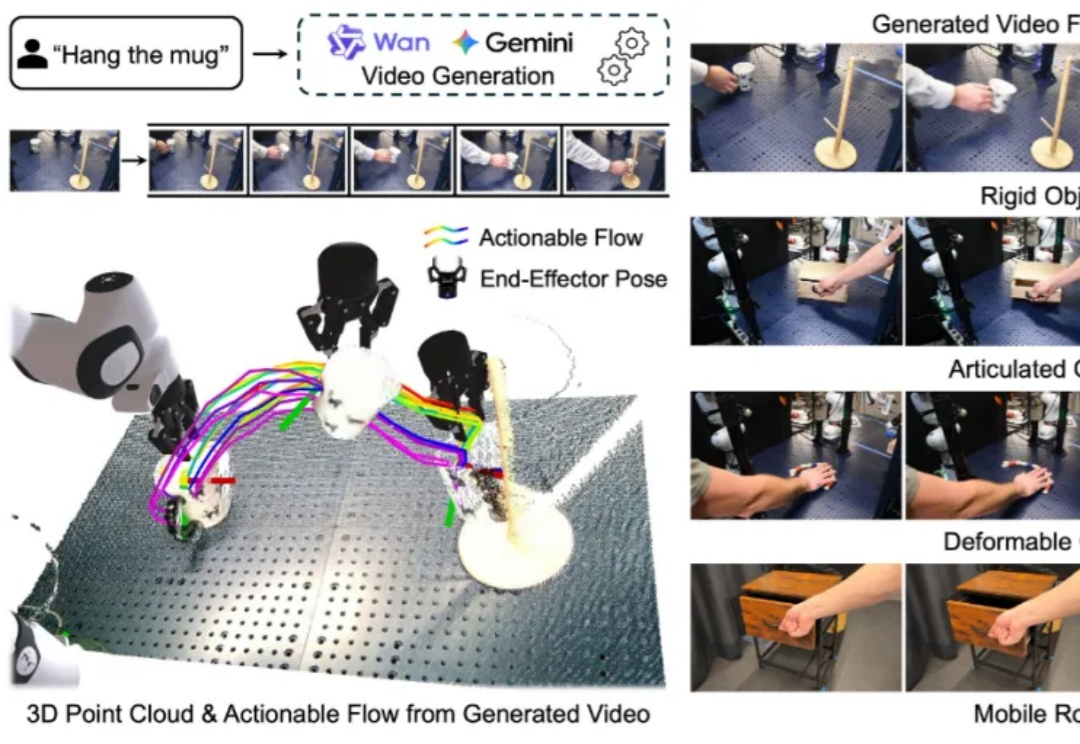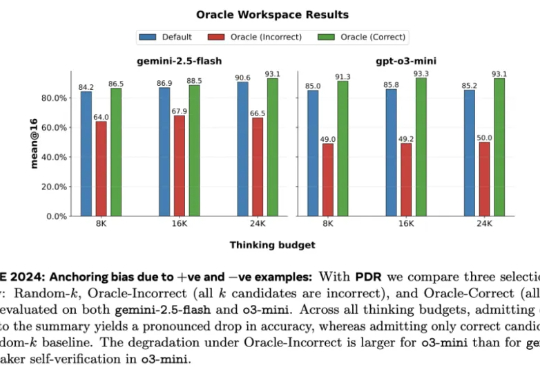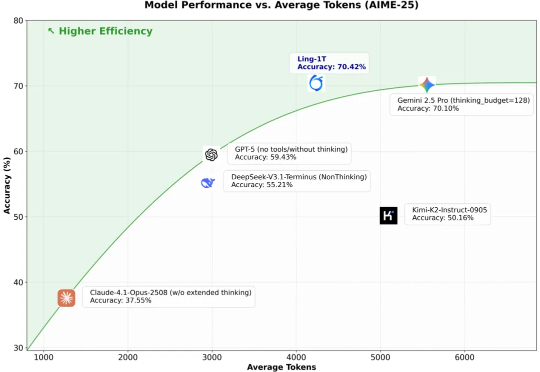
NTU等联合提出A-MemGuard:为AI记忆上锁,投毒攻击成功率暴降95%
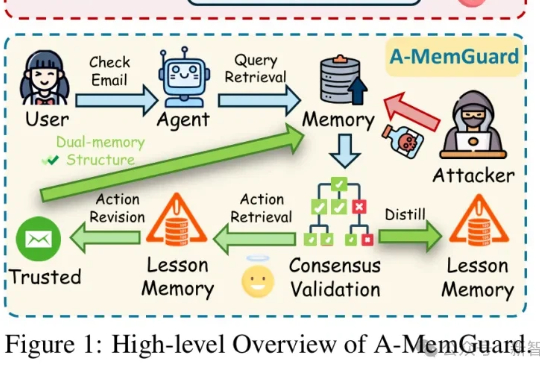
NTU等联合提出A-MemGuard:为AI记忆上锁,投毒攻击成功率暴降95%在AI智能体日益依赖记忆系统的时代,一种新型攻击悄然兴起:记忆投毒。A-MemGuard作为首个专为LLM Agent记忆模块设计的防御框架,通过共识验证和双重记忆结构,巧妙化解上下文依赖与自我强化错误循环的难题,让AI从被动受害者转为主动守护者,成功率高达95%以上。
来自主题: AI技术研报
8400 点击 2025-10-16 14:51